Как отсортировать dataframe по столбцу
pandas.DataFrame.sort_values¶
Sort by the values along either axis.
Parameters by str or list of str
Name or list of names to sort by.
if axis is 0 or вЂindex’ then by may contain index levels and/or column labels.
if axis is 1 or вЂcolumns’ then by may contain column levels and/or index labels.
ascending bool or list of bool, default True
Sort ascending vs. descending. Specify list for multiple sort orders. If this is a list of bools, must match the length of the by.
inplace bool, default False
If True, perform operation in-place.
Choice of sorting algorithm. See also numpy.sort() for more information. mergesort and stable are the only stable algorithms. For DataFrames, this option is only applied when sorting on a single column or label.
na_position <вЂfirst’, вЂlast’>, default вЂlast’
Puts NaNs at the beginning if first ; last puts NaNs at the end.
ignore_index bool, default False
New in version 1.0.0.
Apply the key function to the values before sorting. This is similar to the key argument in the builtin sorted() function, with the notable difference that this key function should be vectorized. It should expect a Series and return a Series with the same shape as the input. It will be applied to each column in by independently.
New in version 1.1.0.
Как сортировать dataframe по столбцу в пандах?
Pandas DataFrame – Сортировать по столбцу
Чтобы сортировать строки DataFrame в столбце, используйте pandas.dataframe.sort_values () Способ с аргументом by = column_name Отказ Метод sort_values () не изменяет исходное dataframe, но возвращает отсортированный dataframe.
Вы можете отсортировать dataframe в порядке возрастания или убывающего порядка значений столбца. В этом руководстве мы будем проходить некоторые примеры программы, где мы будем сортировать dataframe в порядке возрастания или убывания.
Пример 1: сортировка dataframe столбец в порядке возрастания
Порядок сортировки по умолчанию функции сортировки SORT_VALUES () является возрастающим порядком. В этом примере мы создадим dataframe и сортируйте строки определенным столбцом в порядке возрастания.
Вы можете увидеть, что строки сортируются на основе растущего порядка столбца Алгебра Отказ
Пример 2: сортировка DataFrame столбец в порядке убывания
Для сортировки DataFrame в убывании Заказать столбец, пропустите Ascending = false Аргумент для sort_values () метод. Отказ В этом примере мы создадим dataframe и сортируйте строки определенным столбцом в порядке убывания.
Вы можете увидеть, что строки отсортированы на основе уменьшения порядка столбца Алгебра Отказ
Резюме
В этом учебном пособии Pandas мы научились сортировать DataFrame в восходящем и убыточном заказах, используя sort_values (), с помощью хорошо подробных программ Pythone пример.
Pandas Sort — руководство по сортировке данных в Python
Содержание
К концу этого урока вы будете знать, как:
Чтобы понять урок, потребуется базовое знание DataFrames pandas и некоторое представление о чтении данных из файлов.
Начало работы с методами сортировки Pandas ↑
Напоминаем, что DataFrame — это структура данных с помеченными осями для строк и столбцов. Вы можете отсортировать DataFrame по значению строки или столбца, а также по индексу строки или столбца.
И строки, и столбцы имеют индексы, которые представляют собой числовые представления о том, где находятся данные в вашем DataFrame. Вы можете получать данные из определенных строк или столбцов, используя расположение индекса DataFrame. По умолчанию номера индексов начинаются с нуля. Вы также можете вручную назначить собственный индекс.
Подготовка набора данных ↑
В этом уроке будем работать с данными об экономии топлива, собранными Агентством по охране окружающей среды США (EPA) на транспортных средствах, выпущенных в период с 1984 по 2021 год. Набор данных EPA по экономии топлива великолепен, потому что он содержит много различных типов информации, которую вы можете отсортировать, включая текстовую и числовою информацию. Набор данных содержит всего восемьдесят три колонки.
Чтобы продолжить, вам понадобится установленная библиотека Python pandas. Код в этом руководстве был выполнен с использованием pandas 1.2.0 и Python 3.9.1.
Примечание. Полный набор данных по экономии топлива составляет около 18 МБ. Чтение всего набора данных в память может занять минуту или две. Ограничение количества строк и столбцов повысит производительность, но все равно потребуется несколько секунд, прежде чем данные будут загружены.
Для анализа будем просматривать данные о MPG (миля на галлон) для транспортных средств по маркам, моделям, годам и другим характеристикам транспортных средств. Можно указать, какие столбцы следует читать в DataFrame. Для этого урока вам понадобится только часть доступных столбцов. Вот команды для чтения соответствующих столбцов набора данных по экономии топлива в DataFrame и для отображения первых пяти строк:
Индекс строки DataFrame обведен синим на рисунке выше. Индекс не считается столбцом, и обычно у вас есть только один индекс строки. Индекс строки можно рассматривать как номера строк, которые начинаются с нуля.
Сортировка фрейма данных по одному столбцу ↑
Сортировка по столбцу в порядке возрастания ↑
Изменение порядка сортировки ↑
Выбор алгоритма сортировки ↑
Примечание. В pandas kind игнорируется при сортировке более чем по одному столбцу или метке.
Когда вы сортируете несколько записей с одним и тем же ключом, стабильный алгоритм сортировки сохранит исходный порядок этих записей после сортировки. По этой причине использование стабильного алгоритма сортировки необходимо, если вы планируете выполнять несколько сортировок.
Сортировка фрейма данных по нескольким столбцам ↑
При анализе данных часто бывает необходимо отсортировать данные на основе значений нескольких столбцов. Представьте, что есть набор данных с именами и фамилиями людей. Было бы разумно отсортировать по фамилии, а затем по имени, чтобы люди с одинаковой фамилией располагались в алфавитном порядке в соответствии с их именами.
Сортировка по нескольким столбцам в порядке возрастания ↑
Теперь DataFrame отсортирован в порядке возрастания по марке. Если есть две или более одинаковых марок, то они сортируются по моделям. Порядок, в котором имена столбцов указаны в списке, соответствует тому, как будет сортироваться DataFrame.
Изменение порядка сортировки столбцов ↑
Поскольку при сортировке используется несколько столбцов, можно указать порядок сортировки столбцов. Если необходимо изменить логический порядок сортировки из предыдущего примера, то можно изменить порядок имен столбцов в списке, который передаётся параметру by :
Сортировка по нескольким столбцам в порядке убывания ↑
До этого момента мы сортировали несколько столбцов только в порядке возрастания. В следующем примере выполним сортировку в порядке убывания по столбцам марки и модели. Для сортировки в порядке убывания установите значение ascending в False :
Значения в столбце make указаны в обратном алфавитном порядке, а значения в столбце model — в порядке убывания для всех автомобилей той же марки. Для текстовых данных сортировка чувствительна к регистру, то есть текст с заглавной буквы будет отображаться первым в порядке возрастания и последним в порядке убывания.
Сортировка по нескольким столбцам с разными порядками сортировки ↑
Сортировка фрейма данных по его индексу ↑
Сортировка по индексу в порядке возрастания ↑
Сортировка по индексу в порядке убывания ↑
Изучение расширенных концепций сортировки индекса ↑
В анализе данных есть много случаев, когда необходимо сортировать по иерархическому индексу. Вы уже видели, как использовать марку и модель в мультииндексе. Для этого набора данных можно также использовать столбец id в качестве индекса.
Сортировка столбцов фрейма данных ↑
Работа с осью DataFrame ↑
Использование меток столбцов для сортировки ↑
Столбцы вашего DataFrame сортируются слева направо в возрастающем алфавитном порядке. Если вы хотите отсортировать столбцы в порядке убывания, вы можете использовать ascending = False :
Работа с отсутствующими данными при сортировке в Pandas ↑
Вот как выглядит DataFrame при сортировке по столбцу с отсутствующими данными:
Теперь любые недостающие данные из столбцов, которые использовались для сортировки, будут отображаться в верхней части DataFrame. Это особенно полезно при начале анализа своих данные, когда нет уверенности в том, есть ли пропущенные значения.
Использование методов сортировки для изменения фрейма данных ↑
Заключение ↑
Эти методы — значимая часть навыков анализа данных. Они помогут вам построить прочный фундамент, на котором можно выполнять более сложные операции с pandas. Если вы хотите увидеть несколько примеров более продвинутого использования методов сортировки pandas, документация pandas — отличный ресурс.
Основы Pandas №3 // Важные методы форматирования данных
Примечание: это руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Merge в pandas («объединение» Data Frames)
В реальных проектах данные обычно не хранятся в одной таблице. Вместо нее используется много маленьких. И на то есть несколько причин. С помощью нескольких таблиц данными легче управлять, проще избегать «многословия», можно экономить место на диске, а запросы к таблицам обрабатываются быстрее.

Теперь нужно объединить два эти Data Frames в один. Чтобы получилось нечто подобное:

В этой таблице можно проанализировать, например, сколько животных в зоопарке едят мясо или овощи.
Как делается merge?

Теперь пришло время метода merge:
(А где же все львы? К этому вернемся чуть позже).
Это было просто, не так ли? Но стоит разобрать, что сейчас произошло:
Это то же самое, что и:
Разница будет лишь в порядке колонок в финальной таблице.
Способы объединения: inner, outer, left, right
Базовый метод merge довольно прост. Но иногда к нему нужно добавить несколько параметров.
Один из самых важных вопросов — как именно нужно объединять эти таблицы. В SQL есть 4 типа JOIN.

В случае с merge в pandas в теории это работает аналогичным образом.
При выборе INNER JOIN (вид по умолчанию в SQL и pandas) объединяются только те значения, которые можно найти в обеих таблицах. В случае же с OUTER JOIN объединяются все значения, даже если некоторые из них есть только в одной таблице.

В этот раз львы и жирафы вернулись. Но поскольку вторая таблица не предоставила конкретных данных, то вместо значения ставится пропуск ( NaN ).
Теперь в таблице есть вся необходимая информация, и ничего лишнего. how = ‘left’ заберет все значения из левой таблицы ( zoo ), но из правой ( zoo_eats ) использует только те значения, которые есть в левой.
Еще раз взглянем на типы объединения:
Примечание: «Какой метод merge является самым безопасным?» — самый распространенный вопрос. Но на него нет однозначного ответа. Нужно решать в зависимости от конкретной задачи.
Merge в pandas. По какой колонке?
Например, последний merge мог бы выглядеть следующим образом:
Примечание: в примере pandas автоматически нашел ключевые колонки, но часто бывает так, что этого не происходит. Поэтому о left_on и right_on не стоит забывать.
Merge в pandas — довольно сложный метод, но остальные будут намного проще.
Сортировка в pandas
Сортировка необходима. Базовый метод сортировки в pandas совсем не сложный. Функция называется sort_values() и работает она следующим образом:

Единственный используемый параметр — название колонки, water_need в этом случае. Довольно часто приходится сортировать на основе нескольких колонок. В таком случае для них нужно использовать ключевое слово by :

sort_values сортирует в порядке возрастания, но это можно поменять на убывание:

reset_index()
Заметили ли вы, какой беспорядок теперь в нумерации после последней сортировки?

Это не просто выглядит некрасиво… неправильная индексация может испортить визуализации или повлиять на то, как работают модели машинного обучения.

Можно заметить, что новый DataFrame также хранит старые индексы. Если они не нужны, их можно удалить с помощью параметра drop=True в функции:

Fillna
Примечание: fillna — это слова fill( заполнить) и na(не доступно).
Запустим еще раз метод left-merge:

Проверьте себя
Примечание: в этом наборе хранятся данные из блога о путешествиях. Загрузить его можно здесь. Или пройти весь процесс загрузки, открытия и установки из первой части руководства pandas.
Набор article_read показывает всех пользователей, которые читают блог, а blog_buy — тех, купил что-то в этом блоге за период с 2018-01-01 по 2018-01-07.
Решение задания №1
Средний доход — 1,0852
Для вычисления использовался следующий код:

Примечание: шаги использовались, чтобы внести ясность. Описанные функции можно записать и в одну строку.`
Решение задания №2

Найдите топ-3 страны на скриншоте.
Итого
9 первоклассных функций Pandas Python для работы с данными

Pandas — одна из наиболее востребованных библиотек Python в повседневной работе с данными. Подобно Numpy она царствует в таких областях программирования, как наука о данных, МО, ИИ, опираясь на свои многочисленные искусно созданные методы, атрибуты и функции. Изо дня в день анализируя данные, мы сталкиваемся с разными незаурядными ситуациями, решения которых находятся сокровищнице встроенного API Pandas и реализуются посредством краткого и качественного кода.
В статье я поделюсь простыми, но очень эффективными приемами, которые превратят процесс программирования в удовольствие. Именно благодаря этим первоклассным функциям Pandas так полюбилась ученым по данным и инженерам МО.
Нижепредставленный датафрейм позволит прояснить ряд концепций, в других же примерах обойдемся без вспомогательных средств.
 Изображение автора
Изображение автора  Изображение автора
Изображение автора
1. Сортировка данных по убыванию и возрастанию
В Pandas есть встроенная функция sort_values() для сортировки значений столбца или индекса в порядке возрастания или убывания. Отсортируем столбцы разными способами: один в порядке возрастания, а другой — убывания.
В следующем примере столбец “Continent” отсортирован по возрастанию, а “City Population” — по убыванию (второй уровень сортировки работает с соответствующими значениями первого уровня).
 Изображение автора
Изображение автора  Изображение автора
Изображение автора
Аналогичным способом можно создать больше уровней сортировки, перечислив в одном списке имена столбцов, а в другом — соответствующий порядок. Используйте ключевые слова “ by ” и “ ascending ”, как показано ниже (имя каждого столбца в первом списке соотносится с порядком сортировки во втором).
 Изображение автора
Изображение автора
2. shift() для смещения данных
Допустим, ситуация требует сместить все строки в датафрейме или отобразить в нем цену акций предыдущего дня. Перед нами может стоять задача вывести среднюю температуру последних трех дней. Так вот shift() идеально подходит для всех этих целей.
Данная функция в Pandas сдвигает индекс на желаемое число периодов. Она принимает скалярный параметр под названием период, который представляет число сдвигов по требуемой оси. shift() пригодится для работы с данными временных рядов. Можно воспользоваться fill_value для заполнения за пределами граничных значений.
 Изображение автора
Изображение автора
При необходимости вывести цену акций предыдущего дня в новом столбце применяем shift() следующим образом:
Мы можем легко вычислить среднюю цену акций за три последних дня и создать новый столбец, как показано ниже:
Датафрейм приобретает такой вид:
Можно пойти дальше и получить значение из следующего временного интервала или ряда:
В этом случае датафрейм будет выглядеть так:
Более подробная информация о данной функции доступна в документации Pandas.
3. Добавление нового столбца в заданном месте датафрейма
С помощью Pandas мы довольно часто создаем новые столбцы для датафрейма. По умолчанию каждый такой столбец добавляется к нему с конца. Создадим новый столбец со значениями плотности населения для представленных в датафрейме городов (“City Population” / “City Area”). Новое поле по умолчанию будет выглядеть так:
 Изображение автора
Изображение автора
 Изображение автора
Изображение автора
4. value_counts() для нахождения уникальных значений
Функция Pandas value_counts() возвращает объект, содержащий число уникальных значений. Полученный объект можно отсортировать по убыванию или возрастанию, включая или исключая NA посредством управления параметрами. Данная функция применяется с индексом или сериями Pandas.
 Изображение автора
Изображение автора
Ниже представлен пример серии:
Можно воспользоваться опцией bin вместо подсчета уникальных значений и разделить индекс в указанном количестве полуоткрытых интервалов.
Более подробная информация о данной функции представлена в документации Pandas.
5. Выбор столбца на основе типа данных
Сначала с помощью встроенного атрибута dtypes выясним, какие типы данных присутствуют в датафрейме.
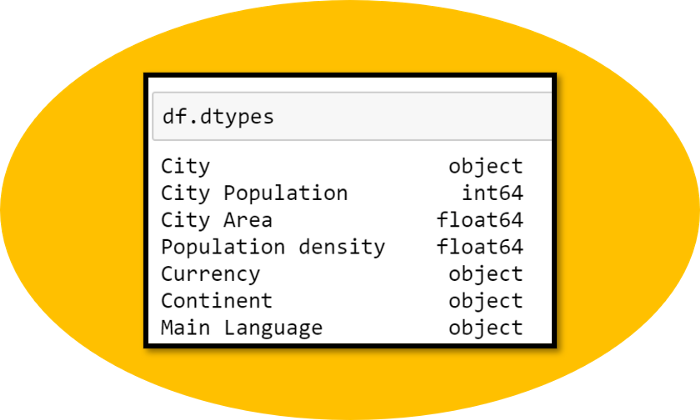 Изображние автора
Изображние автора
 Изображение автора
Изображение автора
Также можно воспользоваться exclude для выбора всех типов данных, кроме исключенных. Например, в этом примере уберем все типы данных object :
 Изображение автора
Изображение автора
Исключение или включение нескольких типов данных происходит посредством списка. Помимо этого, допускаются комбинации этих операций.

6. mask() для условия if-else
 Изображение автора
Изображение автора
Обратимся к датафрейму, в котором нужно изменить знак всех элементов, кратных двум без остатка.
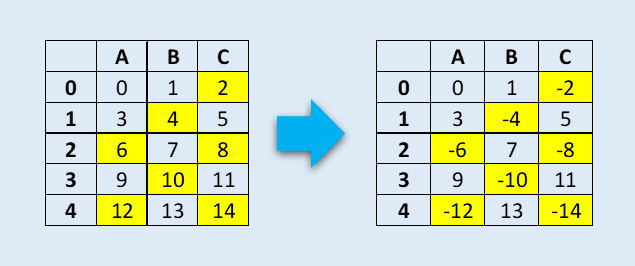 Изображение автора
Изображение автора
Более подробная информация о данном методе предоставлена в документации Pandas.
7. Фильтрация столбцов на основе частичного совпадения
 Изображение автора
Изображение автора
Далее рассмотрим примеры, в которых мы получаем требуемые результаты:
 Изображение автора
Изображение автора
8. nlargest() для определения наибольших значений
Зачастую требуется найти три наибольших или пять наименьших значений в сериях или датафрейме (например, трех лучших студентов с их суммарным баллом или трех худших кандидатов с общим числом голосов, полученных на выборах).
Далее следует пример, отображающий 3 наибольших значения высоты в датафрейме из 10 имеющихся результатов измерения:
 Изображение автора
Изображение автора
При наличии повторяющихся значений опции first , last , all помогают выбрать нужные (по умолчанию first ). Оставим все три полученных варианта и попробуем найти 2 наибольших значения высоты, как показано в примерах:
 Изображения автора
Изображения автора
Оставляем последнее значение с конца:
Оставляем первое полученное значение:
С более подробной информацией о данной функции можно ознакомиться в документации Pandas.
9. nsmallest()
nsmallest() работает аналогичным образом, но только в отношении наименьших значений. В следующих примерах найдем 2 наименьших значения веса:
Документация Pandas содержит более подробную информацию о данной функции.
Заключение
Рассмотренные функции Pandas отличаются не только эффективностью, но также содержательностью, простой и краткостью. С течением лет API Pandas подвергся серьезной доработке и теперь предоставляет множество встроенных функций, требующих немало строк кода, или лямбда-функций для выполнения требуемых операций с данными. Надеюсь, материал был вам полезен.